Documentation Index
Fetch the complete documentation index at: https://docs.codatta.io/llms.txt
Use this file to discover all available pages before exploring further.
AI를 위한 데이터 기초
샘플(수학 표기: X): 모델이 학습할 입력 관측치(이미지, 오디오 클립, 텍스트 스팬, 시계열 윈도우, 멀티센서 프레임 등). 레이블(수학 표기: Y 또는 y): 샘플(또는 샘플 그룹)에 대한 구조적 해석: 클래스, 바운딩 박스, 세그멘테이션 마스크, 스팬, 평점, 관계, 시간에 따른 사건 등. 검증(Validation): 샘플이나 레이블에 대한 품질 판단 또는 증거 점검. 합의 투표, 루브릭 채점, 재레이블링, 자동 점검 + 휴먼 판정 등을 포함할 수 있습니다. 모델에 품질이 중요한 이유- 신호 대 잡음비 – 잘못된 레이블 또는 정보량이 낮은 데이터는 유효 배치 크기를 줄이고 수렴을 늦춥니다.
- 바이어스 & 누수 – 불일치한 스키마, 숏컷 피처, 레이블 누수는 일반화와 공정성을 해칩니다.
- 이질적 과제 – 멀티태스크/Chain-of-Thought 모델은 명확하고 일관된 지시와 추적 가능한 출처에 의존하여 디버깅과 개선을 수행합니다.
Codatta의 데이터 모델
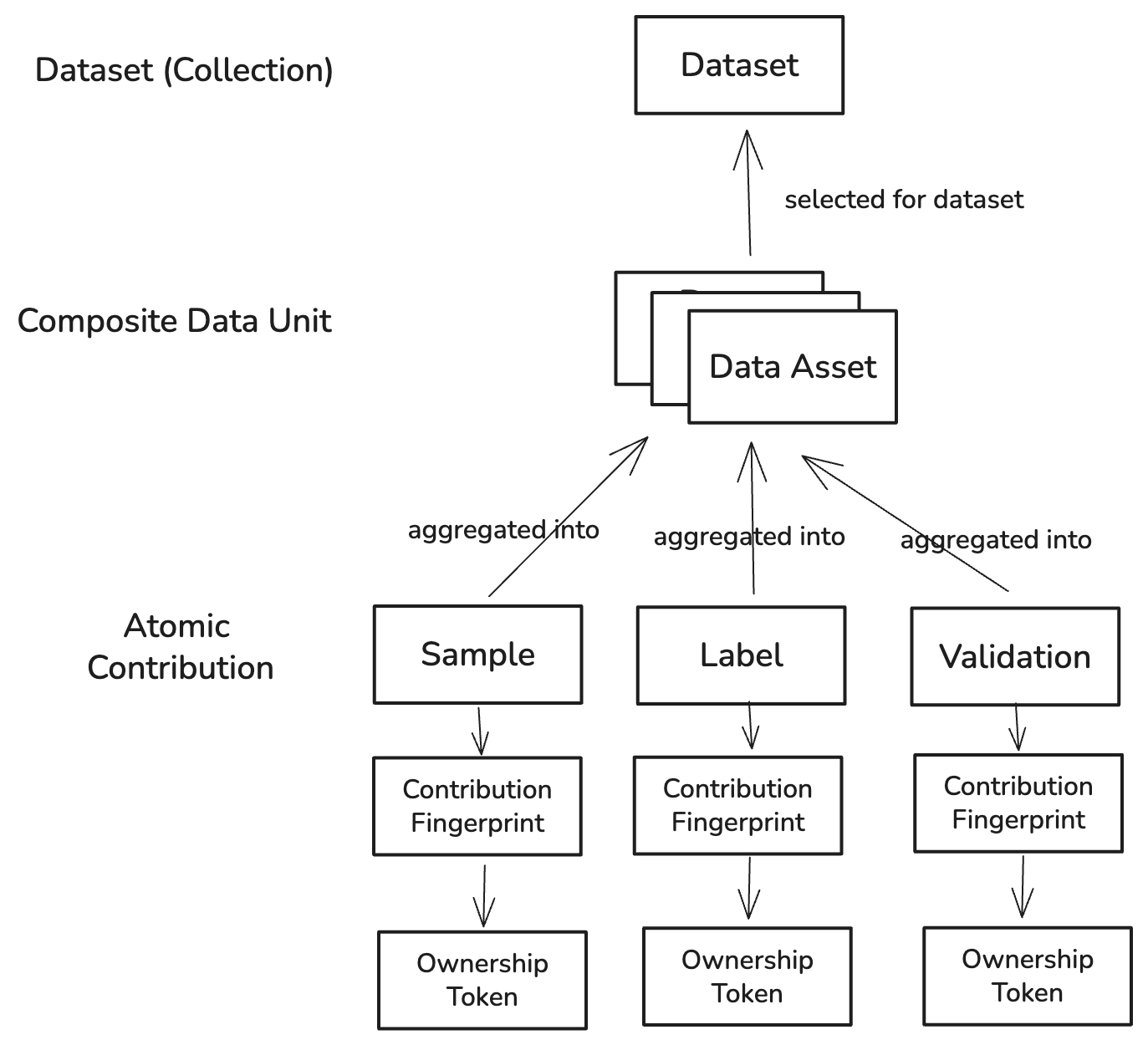
왜 중요한가: 데이터 자산은 소유권 & 로열티의 단위이자, 실제 구매자가 소비하는 라이선스 단위입니다.
사람 또는 에이전트가 만든 하나의 작업 단위:
sample– 관측치label– 해석validation– 품질/증거 판단
- 누가, 언제, 무엇을, 어떤 페이로드에 했는지를 증명하는 변조 방지 식별자(해시 + 메타데이터 + 부모 링크)
- CF는 기여를 발견 가능, 중복 제거 가능, 감사 가능하게 만듭니다.
서로 연관된 AC를 모아 만든 합성된 최소 상업 단위(예: 한 이미지 + 승인된 레이블 + 검증). 소유권과 라이선스는 자산 수준에서 집행되며, 이는 AI 팀이 실제 사용하는 단위입니다. C. 데이터셋(뷰/컬렉션)
특정 모델, 버티컬, 평가 목적에 맞춘 데이터 자산의 큐레이션된 선택—저장된 쿼리나 매니페스트로 정의됩니다. 데이터셋은 포함된 자산의 소유권, 라이선스, 계보를 모두 상속합니다.
전형적 시나리오
시나리오 A: 하나의 샘플, 여러 레이블 세트
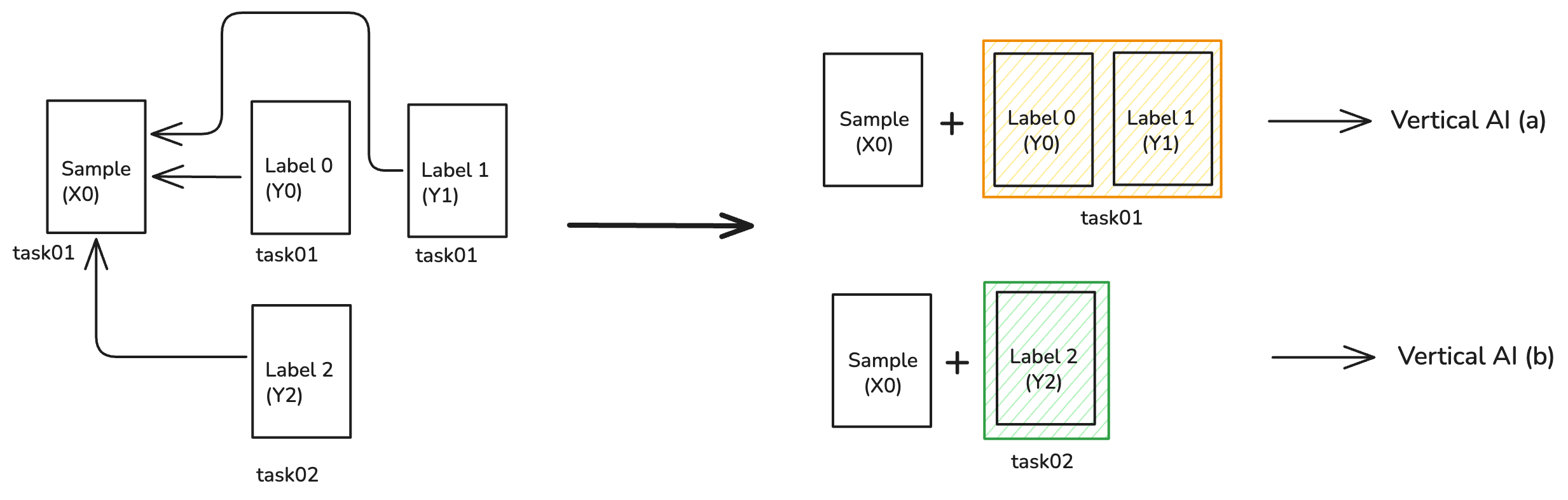
X0 + {Y0, Y1}를 묶으면 자산-A(버티컬 AI “a”), X0 + {Y2}를 묶으면 자산-B(버티컬 AI “b”).
왜 중요한가: 동일한 원시 샘플이라도 서로 다른 레이블 번들을 묶으면 서로 다른 제품을 만들 수 있으며, 각각의 로열티/라이선스 조건이 달라집니다.
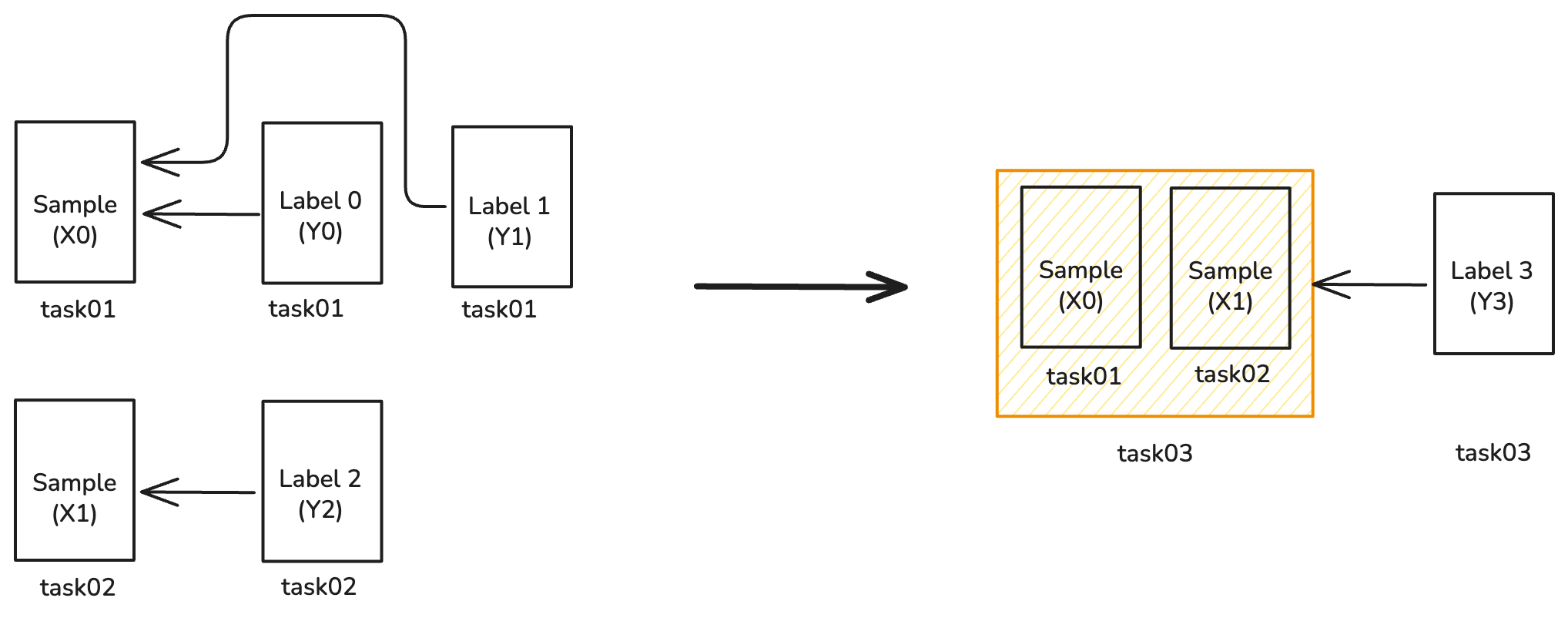
시나리오 B: 교차-샘플 합성
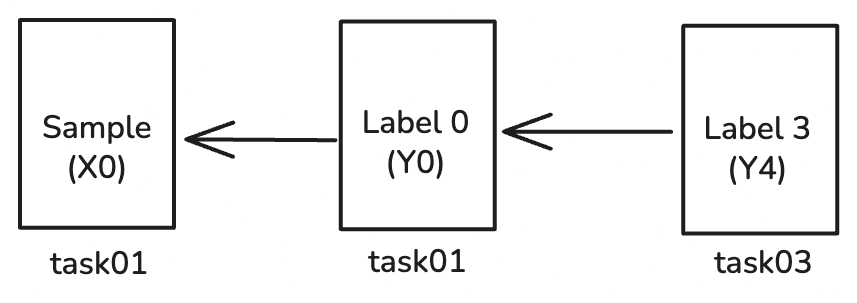
시나리오 C: 레이블 위의 레이블(메타 레이블링)
자산화 & 블록체인 기술
왜 자산화인가?전통적 레이블링 산출물은 추적·공유·가치 산정이 어렵습니다. 자산화는 작업을 출처와 프로그래머블 권리를 가진 온체인 객체로 전환합니다:
- 기여 지문(CF)(해시 + 메타데이터 + 부모)로 출처 확보 → 누가, 언제, 무엇을, 어떤 페이로드에 했는지.
- 파일이 아닌 데이터 자산에 대한 **분수 토큰(fractional token)**으로 소유권을 표현하여 다수의 기여자/검증자가 수익에 참여.
- 라이선스 & 계량: 정책 기반 접근(공개 vs 제한), 읽기/훈련/추론 사용 영수증이 로열티 라우팅을 구동.
- 파생(derivation): 상속 규칙을 전파(자식 자산은 부모를 가리키고, 로열티는 정책에 따라 전파).
- 프라이버시 설계: 하이브리드 스토리지 + 시큐어 컴퓨트(예: TEE)로 원본을 노출하지 않고 사용 가능.
- 신뢰 최소화: 기여·소유권·사용 이벤트의 공개 Append-only 기록.
- 조합성: 계보와 분배를 보존하면서 자산을 질의·번들·재라이선스 가능.
- 인센티브: 자산이 사용되면 기여자와 검증자가 수익을 얻어 품질과 장기 가치가 정렬됩니다.