TL;DR
This page builds shared language for the rest of the docs. It explains how AI uses samples, labels, validations, how Codatta models them as atomic contributions, how they bundle into a data asset (the minimal commercial unit), and why we use blockchain to make assetification & royalties programmable.Data basics for Artificial Intelligence (AI)
Sample (math notion: X): A raw observation the model will learn from (image, audio clip, text span, time series window, multi-sensor frame, etc.). Label (math notion: Y or y): A structured interpretation of a sample (or group of samples): class, bounding box, segmentation mask, span, rating, relation, events over time, etc. Validation: A quality judgment or evidence check on a sample or label. This can be consensus voting, rubric scoring, re-labeling, or automated checks plus human adjudication. Why quality matters to models- Signal-to-noise – mislabeled or low-information data reduces effective batch size and slows convergence.
- Bias & leakage – inconsistent schema, shortcut features, or label leakage harm generalization and fairness.
- Heterogeneous tasks – multi-task/chain-of-thought models depend on clear, consistent instructions and traceable provenance to debug and improve.
Codatta’s data model
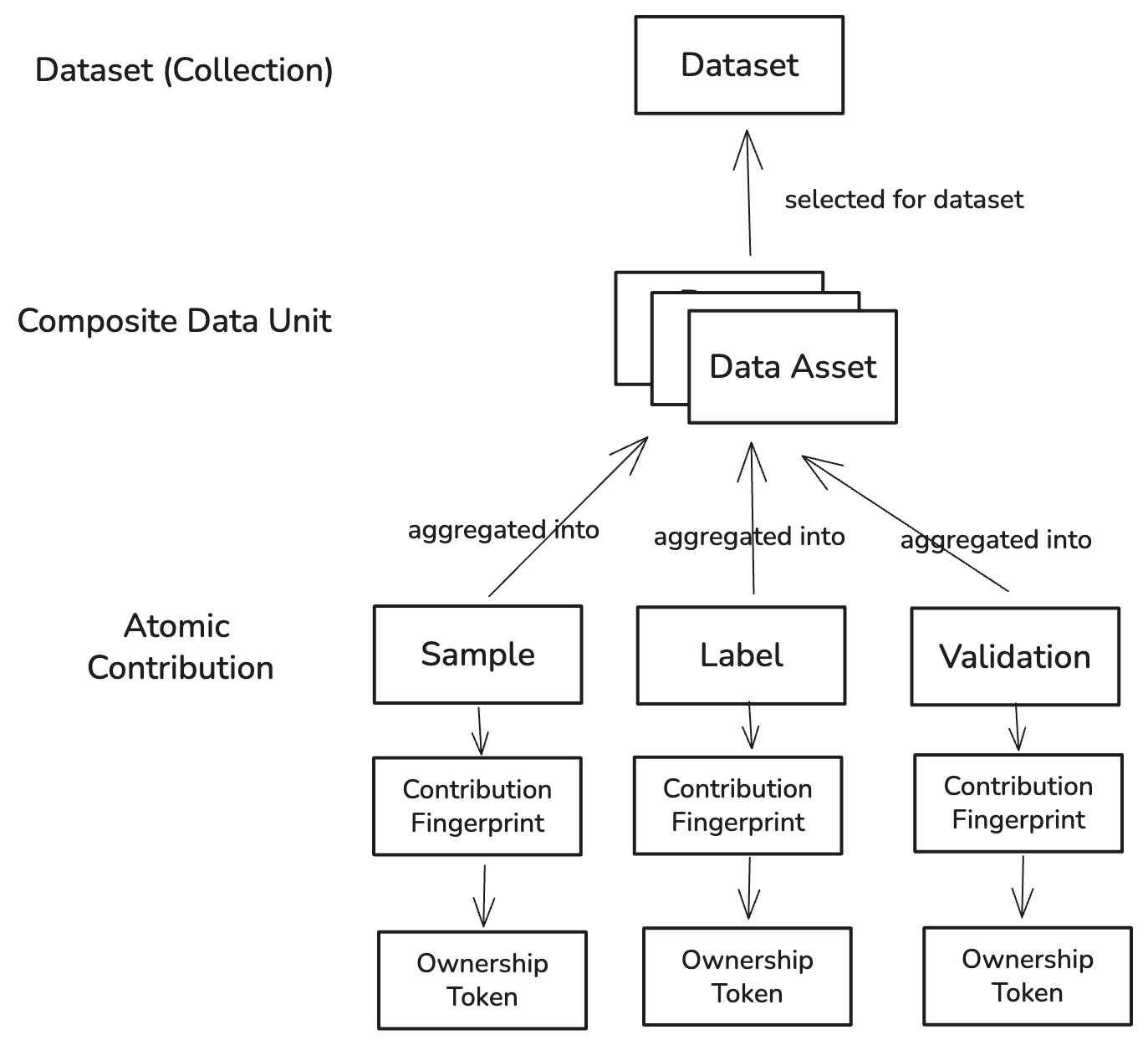
Why it matters: The Data Asset is the unit of ownership & royalty and
the unit of licensing most buyers actually consume.
One unit of work produced by a human or agent:
sample– the observationlabel– the interpretationvalidation– the quality/evidence decision
- A tamper-evident identifier (hash + metadata + parent links) that proves who did what, when, to which payload.
- CFs make contributions discoverable, deduplicable, and auditable.
A composite, minimal commercial unit created by aggregating ACs that belong together (e.g., one image + its accepted labels + validations). Ownership and licensing are enforced at the asset level because that’s what AI teams actually use. C. Dataset (View / Collection)
A curated selection of Data Assets for a particular model, vertical, or evaluation—defined by a saved query or manifest. Datasets inherit all ownership, licensing, and lineage from the assets they include.
Typical real-world scenarios
The figures below are conceptual and focus on relationships and flow; field
names and formats may evolve as the protocol is finalized.
Scenarion A: One sample, multiple label sets
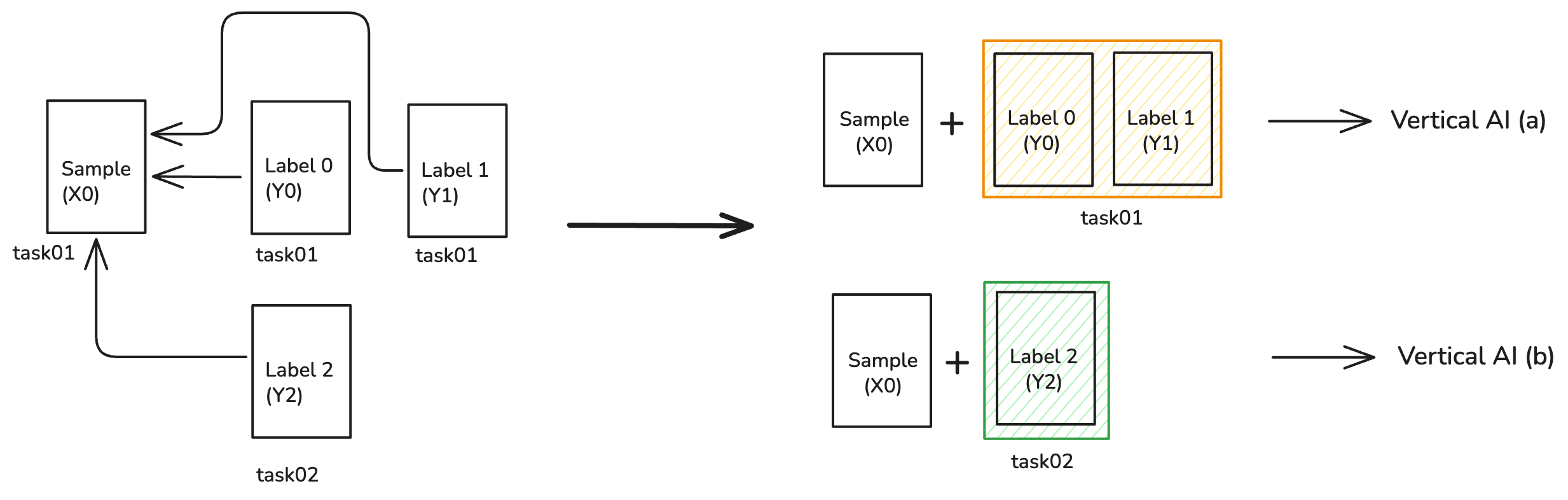
X0 + {Y0, Y1} forms Asset-A (Vertical AI “a”), while bundling X0 + {Y2}
forms Asset-B (Vertical AI “b”).
Why it matters: The same raw sample can power different products simply by
bundling different labels—each with its own royalties and license terms.
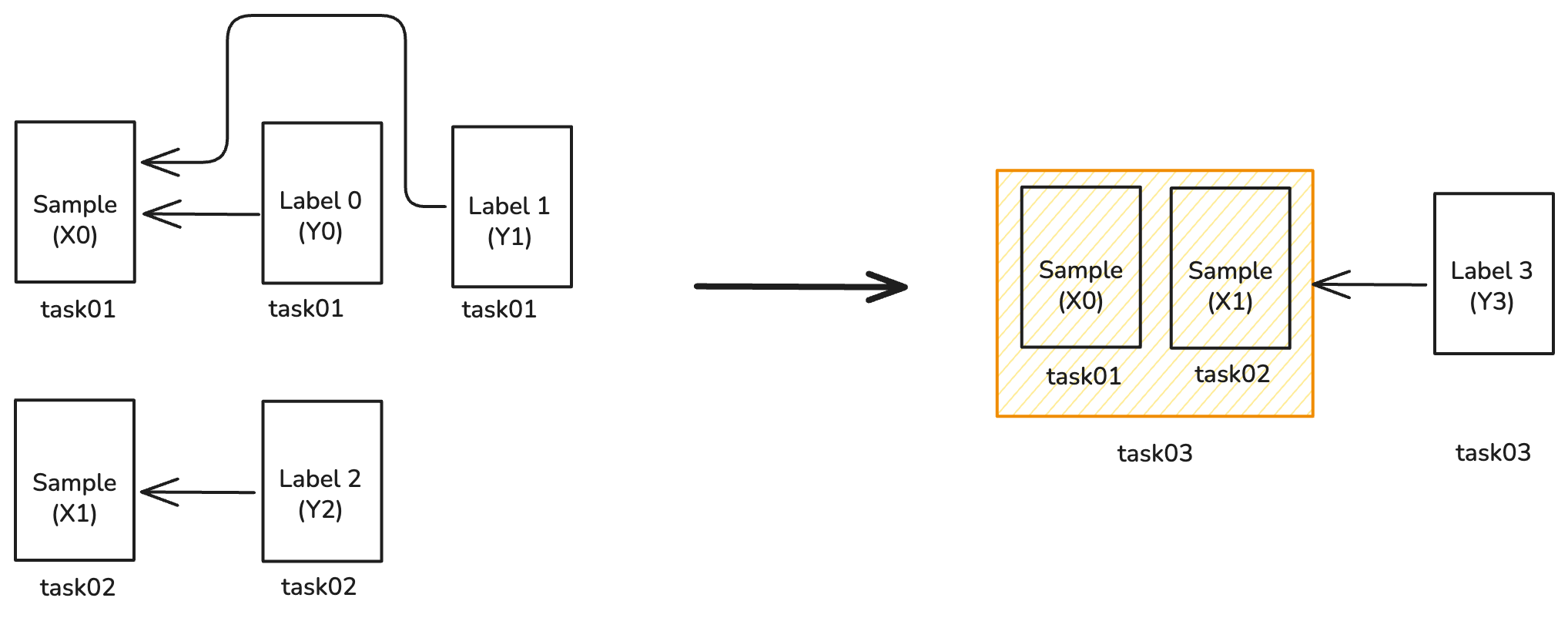
Scenarion B: Cross-sample composite
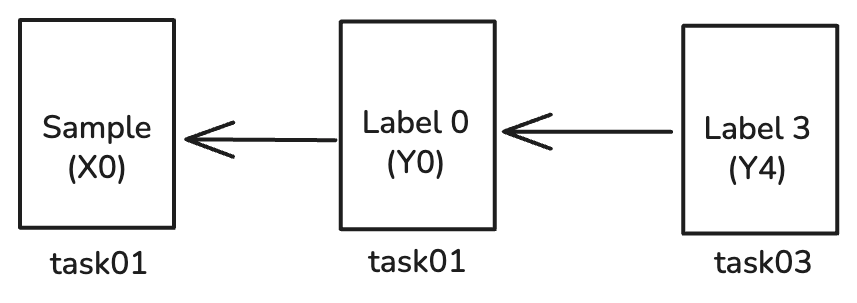
Scenarion C: Label-on-label (meta-labeling)
Assetification & blockchain technology
Why assetify?Traditional labeling produces files that are hard to track, share, or value. Assetification turns work into on-chain objects with provenance and programmable rights:
- Provenance via Contribution Fingerprints (hash + metadata + parents) → who did what, when, to which payload.
- Ownership via fractional tokens on Data Assets (not just on files), so multiple contributors/validators can participate in revenue.
- Licensing & metering with policy-gated access (public vs. restricted), and usage receipts (read/train/infer) that drive royalty routing.
- Derivation that carries inheritance rules (child assets point to parents; royalties propagate per policy).
- Privacy-by-design: hybrid storage + secure compute (e.g., TEEs) so models can use data without exposing raw content.
- Trust minimization: public, append-only record of contributions, ownership, and usage events.
- Composability: assets can be queried, bundled, and re-licensed across apps while preserving lineage and payouts.
- Incentives: contributors and validators earn when assets are used—aligning quality with long-term value.